
Data lakes and data warehouses, while not interchangeable terms are both widely used for storing data. In fact, they are more different than they are alike.
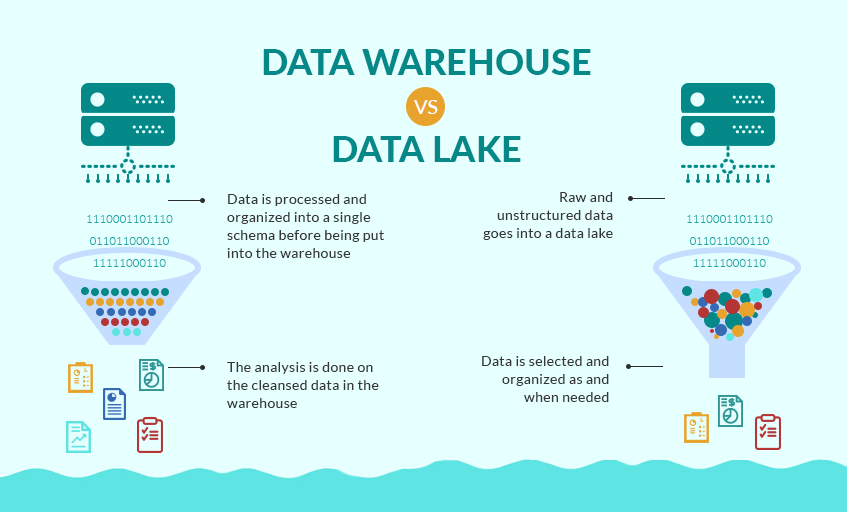
A data lake is a pool of raw data that is unstructured and has no transformation when it is stored. A data warehouse, on the other hand, is structured and transformed data that is stored for a specific purpose.
Understanding that the two are different is fundamental as they are utilized by the end-user in two different ways. While a data lake works best in one scenario, a data warehouse could be a better fit in another.
Cleaning and organizing data is a time-consuming process so ensuring it is stored for easy retrieval is particularly important. Changes to the data after it has been loaded can be tedious and costly.
Understanding the concept of structured and unstructured data is the fundamental difference between lakes and warehouses.
Unstructured data is raw, messy, and imperfect. Most of the data in the world, like photos, chat logs, and PDF files are unstructured data. Data lakes were designed to store this type of unstructured data.
Data warehouses store historical data that has been cleaned to fit a relational schema. Data organized into tables with defined types and relationships is called structured data.
It’s not uncommon for a company to have both a data lake and a data warehouse.
Data lakes and data warehouses can complement each other in their data workflow. For example, a company would store data immediately into the data lake. Then, when the company has defined rules for a specific business question, specific data can be cleaned and exported into the data warehouse.
Data lakes are cost-effective for large amounts of data from many sources. Since a data lake does not have any specific schema, ingesting large amounts of data can be done at a lower cost. The costs are lower due to the lake’s flexibility and scalability. There are downsides, like storing data that is never used or storing so much data that it causes complexity and confusion when trying to utilize it for decision making.
Data warehouses, however, are less complex to use as they have structured data that is easier to analyze, is cleaner, and has a uniform schema-to-query from. Because they restrict data to a schema, data warehouses are very efficient for analyzing historical data for specific data decisions.
Data Lake vs. Data Warehouse Comparison Table
| Data Lake | Data Warehouse | |
| Data Structure | Raw (unstructured) | Processed (structured) |
| Processing | Schema-on-read | Schema-on-write |
| Data Processing | ELT – Extract Load Transform | ETL – Extract Transform Load |
| Size | Stores all data that might be used | Stores data relevant to current analysis needs only |
| History | Big data that is new | Structured data with years of history |
| Users | Data Scientists | Data & Business Analysts |
| Accessibility | Highly accessible & easy to update | More complicated & costly to
make changes |
| Cost | $ | $$$ |
Data and business analysts most often work with data warehouses as they require a lower level of programming. These analysts typically rely on years’ worth of history to report on during analysis. This is most easily retrieved in a defined schema where retrieval of years’ worth of results happens very quickly.
Data warehouses are typically set to read-only. Data or business analyst users are primarily reading and aggregating data for reporting and insights. Data updated once a day or only monthly might be all that is needed in certain scenarios. However, it is expected that the data is already cleaned and inserted per the defined schema.
More often, data scientists will work with data lakes as they contain data of a wider and more current scope. In addition, data scientists have more advanced programming skills that will utilize services designed specifically for interpreting big data. Data scientists run big data analytics on data lakes using services such as Apache Spark and Hadoop. This is especially true when working with deep learning, machine learning, and AI.
Nearly everyone is touched by these technologies as you can find them in your music streaming services that recommend the next song based on other listeners’ tastes. Because of these new technologies, data lakes have much higher latency and sensitivity to the speed that they can be accessed.
It should be no surprise that data lakes are much bigger in size because they retain any data that might be relevant to a company. Data lakes are often petabytes in size—that’s 1,000 terabytes! Data warehouses are much more selective on what data is stored.
As the amount of unstructured data rises, the data lake will become increasingly popular. But there will always be an essential place for data warehouses.
You’ll probably continue to keep your structured data in the data warehouse. However, as more companies move their unstructured data to data lakes on the cloud (where it’s more cost-effective to store it and easier to move it when needed) you might reconsider.
When you’re deciding between a data lake or data warehouse, use the included table and see which option best fits your use case.
Pete Audenas
Peter Audenas has been a trusted business partner to small and mid-sized companies for over 30 years. His expertise and proven methodology blends the right people, process, and technology to help business owners grow revenues, increase office efficiencies, and decrease costs. Read full bio >>
